

【Adam】パラメータ最適化アルゴリズムAdamを実装するコード【Python】
Adamクラスの定義
Adamでの重み更新は以下のような式になる。
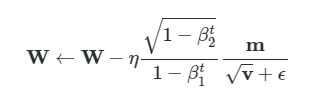
これを実装すると以下のようなコードになる。
Adamクラスを定義する。
# Adam
class Adam:
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
for key in params.keys():
self.m[key] = self.beta1 * self.m[key] + (1 - self.beta1) * grads[key]
self.v[key] = self.beta2 * self.v[key] + (1 - self.beta2) * (grads[key]**2)
m_unbias = self.m[key] / (1 - self.beta1**self.iter)
v_unbias = self.v[key] / (1 - self.beta2**self.iter)
params[key] -= self.lr * m_unbias / (np.sqrt(v_unbias) + 1e-7)Adamを学習で用いるtrain関数で利用する
これをモデル学習で用いるtrain関数内で取り入れると以下のコードになる。
def train(x, t, eps=0.005):
global W, b # 重みとバイアス
batch_size = x.shape[0]
t_hat = softmax(np.matmul(x, W) + b)
cost = (- t * np_log(t_hat)).sum(axis=1).mean()
delta = t_hat - t
dW = np.matmul(x.T, delta) / batch_size
db = np.matmul(np.ones(shape=(batch_size,)), delta) / batch_size
# Adamでパラメータ更新
params = {'W': W, 'b': b}
grads = {'W': dW, 'b': db}
adam.update(params, grads)
return cost基本的なモデル学習を行うプログラムは以下に詳しく書いているので参照↓

参考
人気記事
人気記事はこちら。




